Investigación de Enmacosa dentro del proyecto "Desarrollo y mejora de modelos teóricos del hormigón estructural a partir de su dosificación mediante técnicas de programación genética y redes de neuronas artificiales", cofinanciado por la Xunta de Galicia (2010-2013).
Enmacosa research within the project "Development and improvement of theoretical models of structural concrete from its dosage by genetic programming and artificial neural networks", cofinanced by the Xunta de Galicia (2010-2013).
1 Introducción.
2 Seguimiento - Finalización.
3 método aplicado.
3.1 Fase 1. Identificación de variables clave ..
3.2 Fase 2. Análisis de los resultados
3.3 Fase 3. Aplicación de técnicas de regresión .
4 Resultados alcanzados.
4.1 Base de datos
4.1.1 Resultados.
4.1.2 Caracterización de base de datos
4.2 Variables que afectan a las propiedades del hormigón.
4.2.1 Las variables con alta influencia.
4.2.2 Variables que influyen en los medios de comunicación.
4.2.3 Variables con baja influencia.
4.3 Aplicación de RR.NN.AA. la predicción de parámetros físicos medibles mediante ensayos
4.4 Análisis de la resistencia alcanzado por los diferentes hormigones, en relación con la especificada
4.4.1 Análisis por el fabricante
4.5 Análisis de consistencia obtenidos con respecto como se especifica
4.6 Análisis de la evolución de la resistencia del hormigón con la edad
4.6.1 CEM I 52,5 R
4.6.2 CEM II 42.5 R
4.6.3 I / 52,5 N / SR
4.6.4 III / A 42,5 N / SR
4.6.5 IV / A-V 42,5 N / SR.
4.7 Análisis de la relación y el contenido de agua / cemento con la resistencia del hormigón.
4.8 Predicción del módulo del hormigón - Convencional
5 Publicaciones.
5.1 Mejora de la formulación de la EC-2 para la resistencia al corte en vigas de hormigón Estructural sin armadura.
5.2 Regresión simbólico en Ingeniería Civil a través de técnicas de programación genética.
5.3 Programación Genética para Modelo de Mejora FIB: Bond y Anchorage de refuerzo Acero Estructural en Concrete
6 Bibliografía
2 Seguimiento - Finalización.
3 método aplicado.
3.1 Fase 1. Identificación de variables clave ..
3.2 Fase 2. Análisis de los resultados
3.3 Fase 3. Aplicación de técnicas de regresión .
4 Resultados alcanzados.
4.1 Base de datos
4.1.1 Resultados.
4.1.2 Caracterización de base de datos
4.2 Variables que afectan a las propiedades del hormigón.
4.2.1 Las variables con alta influencia.
4.2.2 Variables que influyen en los medios de comunicación.
4.2.3 Variables con baja influencia.
4.3 Aplicación de RR.NN.AA. la predicción de parámetros físicos medibles mediante ensayos
4.4 Análisis de la resistencia alcanzado por los diferentes hormigones, en relación con la especificada
4.4.1 Análisis por el fabricante
4.5 Análisis de consistencia obtenidos con respecto como se especifica
4.6 Análisis de la evolución de la resistencia del hormigón con la edad
4.6.1 CEM I 52,5 R
4.6.2 CEM II 42.5 R
4.6.3 I / 52,5 N / SR
4.6.4 III / A 42,5 N / SR
4.6.5 IV / A-V 42,5 N / SR.
4.7 Análisis de la relación y el contenido de agua / cemento con la resistencia del hormigón.
4.8 Predicción del módulo del hormigón - Convencional
5 Publicaciones.
5.1 Mejora de la formulación de la EC-2 para la resistencia al corte en vigas de hormigón Estructural sin armadura.
5.2 Regresión simbólico en Ingeniería Civil a través de técnicas de programación genética.
5.3 Programación Genética para Modelo de Mejora FIB: Bond y Anchorage de refuerzo Acero Estructural en Concrete
6 Bibliografía
1. INTRODUCCIÓN
Este informe presenta los logros alcanzados en el proyecto titulado "Desarrollo y mejora de los modelos teóricos de la estructura de hormigón a partir de su forma de dosificación por técnicas de programación y redes genéticas neural artificial ".
En la actualidad la aplicación de técnicas de inteligencia artificial (IA) no es campo no relacionado de la ingeniería. En particular, existen numerosas referencias en uso de las Redes Neuronales Artificiales (RNA) y técnicas Computación Evolutiva (CE) en el ámbito de la Ingeniería Civil (Arciszewski et al. 2001 Kicinger et al. 2005). La ANN es una de las técnicas que simbólica sobresale en la aplicación de técnicas de IA en Ingeniería Civil, se destacan por su capacidad de aprendizaje, la tolerancia y la generalización errores que hacen uso viable y rentable dentro de este campo y, específicamente, en Ingeniería Estructural. Del mismo modo, la computación evolutiva es otras técnicas que se utilizan dentro de este ámbito. dentro de este conjunto de técnicas de pie en algoritmos genéticos un lado (GA) que, como principal virtud es la optimización de los parámetros (por ejemplo, dosificación) y en segundo lugar, la programación genética, que se destaca en este campo de realizar tareas de regresión simbólica y relacionar algebraicamente variables de entrada con la variable objetivo o de salida.
2 SEGUIMENTO - FINALIZACIÓN
El proyecto se concluyó al 100%, a pesar de que hubiera varios hechos que retrasaron en gran medida las tareas planificadas. En el siguiente calendario son las tareas planificadas (P), y lo que realmente se hizo (F). A continuación se enumeran las desviaciones mas importantes del proyecto.

En el primer año no se produjeron grandes desajustes. En el segundo año fue donde se produjeron mayores desajustes motivados principalmente por el conjunto de de datos. Los principales motivos fueron el retraso en la obtención de datos los datos y en la depuración de éstos. Esta depuración fue imprescindible ya que en las primeras pruebas de funcionamiento del sistema (tarea 6) se produjeron incoherencias en los resultados obtenido. En este punto se llegó a la conclusión de que los datos precisaban de un filtrado. Dado el volumen de datos (el la finalización del proyecto se contaba con 73.078 probetas) la depuración consumión mucho tiempo. Por este motivo las demás tareas sufrieron un aplazamiento y retrasos.
El tercer año se centró principalmente en la aplicación de las técnicas de programación genética tanto para los datos obtenidos como con las demás bases de datos conseguidas a lo largo del proyecto.
3 MÉTODO APLICADO
3.1 FASE 1. IDENTIFICACIÓN DE LAS VARIABLES PRINCIPALES.
El primer paso, antes de aplicar cualquier técnica de identificación de variables principales se debe realizar una depuración de la base de datos.
A primera vista puede parecer trivial este preprocesado de datos , pero fundamental para la obtención de resultados coherentes y no sesgados. El preprocesado debe dar como resultado un conjunto de datos correctamente verificado, completo y representativo dentro de los intervalos a estudiar.
Existen multitud de métodos más o menos complejos, para la obtención del conjunto de variables significativas (Yang & Honavar, 1998). O desde el punto de vista contrario: el objetivo de formularse como método de selección de variables debe ser capaz de detectar todas aquellas variables que son irrelevantes y/o redundantes para un problema dado.
Con esto lo que se pretende es crear modelos estables, guiados por el principio que la estadística se denomina principio Occam Razor (Ariew, 1976) El que un aprendizaje automático se conoce como KISS (Keep It as Simple as possible,Stupid). Es decir una idea subyacente a la modelización estable y que existen Los modelos que aplican suficientemente bien un conjunto específico de datos, se debe escoger el modelo más simple de los dos. En este caso que aquí se presentan se identifican las variables más significativas que intervienen en el proceso de fluencia. En esta ocasión se elige la técnica de las RNAs Por su demostrada capacidad de aprendizaje autoorganización y tolerancia de fallos.
Para la realización de las pruebas se dividió en dos el conjunto total de la. Siguiendo el paradigma 80/20 Se empleó para el adiestramiento del 80% de los patrones y para el ensayo el 20% del conjunto total. Para determinar las reglas influyentes en el proceso, en primer lugar se ejecutó una red 10 veces con todas las variables. De esta manera se establece un punto de comparación. A continuación se subdividieron en tantos conjuntos como entradas hay, es decir, se creó un conjunto de todas las variables de entrada menos uno (por Ejemplo, sacando las variables de entrada y cantidad del árido).De esta manera se generaron dos en su conjunto de entradas posibles que se ejecutan 10 veces de la misma manera que con el conjunto total de variables.
3.2 FASE 2. ANÁLISIS DE RESULTADOS
Dados los resultados obtenidos en la fase anterior, se observan las relaciones entre los valores experimentales estableciéndose los valores y ecuaciones que servirán para la segunda fase.
3.3 FASE 3. APLICACIÓN DE TÉCNICAS DE REGRESIÓN.
Una vez determinados los principales factores que intervienen en el proceso de la siguiente fase y la aplicación de técnicas de regresión para obtener una expresión con relación al conjunto de variables sus operadores definidos en las fases anteriores.
Tras la realización de la fase uno identificando, con ayuda de la literatura científica, las variables esenciales para el proceso de estudio, se llegó a la conclusión de que El que no se podría disponer de todas estas variables por lo que el estudio inicial sería en cierto modo limitado en función de la información disponible. En el apartado siguiente pueden verse en detalle los estudios y conclusiones recabados con datos reales obtenidos de 2000 ensayos realizados por ENMACOSA.
4 RESULTADOS ACADADOS
4.1 BASE DE DATOS
Una de las áreas de mayor envergadura des desarrollada en la depuración impuesta. La base de datos., de 4 millones de entradas pertenecientes a los más de 70.000 ensayos realizados en su mayor parte en los procesos de toma de muestras de análisis "in situ" por operarios de ENMACOSA..
La base de datos contenía algunos errores y vicios vinculados entre otros a:
Errores humanos ( se escribe cinco cuando debe ser 50, errores en transcripción de horas)
- Ausencia de datos (campo no cubiertos)
- Indefinición en la denominación de productos (el hormigón de la planta a poder fabricante uno puede escribirse como unión de ambos o descriptores o empleando sólo uno de ellos, produciendo indefinición)
- Defectos en la denominación de los productos ( confusión en la zona de estructura, denominación del tipo de cemento,...)
- ...
En el tratamiento de las bases de datos amplias es fundamental poder clasificar los campos de forma coherente. Cabe destacar que la simple incorporación de un espacio en blanco en la eliminación de cualquier producto proceso hace que la base de datos reconoce este producto como diferente al que se pretendía consignar.
La proporción de roles de cualquier origen de la base de datos fue pequeña aunque mal absoluto supusieron muchos millares de casos.
Se emplearon técnicas diversas en la depuración de la base de datos principalmente basadas en la estadística (media, máximos/mínimos, ...) O corrección de campos mediante tokens o cambio de caracteres.
4.1.1 Resultados
Como resultados tangibles tenemos dos principales. Uno es la base de datos en sí mismo y mejoró sensiblemente su capacidad informativa. Se pone como ejemplo que los tipos de cemento pasaron de 176 (“informáticamente” diferentes) a tan sólo (todos con denominación estándar normativa). Esta depuración inicial, tediosa pero transcendental, Es la que cimentó el análisis posterior. Otro resultado tangible en la transformación de procesos que están constatación provocó en ENMACOSA. La empresa realice una trasformación significativa de sus procesos de producción de datos, mecanizado en lo posible las opciones, como por ejemplo mediante la creación de lista desplegables en lugar de la introducción de datos directamente por el teclado, Siempre con más error.
4.1.2 Caracterización da base de datos.
Con la depuración inicial de los datos contiene un conjunto amplio (Como puede verse en la cantidad de datos por cada variable en la tabla 1). Cabe destacar que no se dispoñe de todos os datos de cada variable.

Tras la depuración inicial se realizó un filtrado de estos datos empleando las siguientes variables en los rangos indicados:
Resistencia característica (MPa): >= 25 <=100
Relación A/C (%): >=0.3 <=0.8
Cantidade de cemento por m3 (kg):< 530
Densidade (kg/m3): >= 1800 <= 2700
Cono de abrams (cm): <= 30
El resultado tras aplicar este filtro fue la reducción de la base de datos hasta llegar a las 70.725 probetas. En las siguientes tablas y gráficos se muestran en detalle la distribución de cada variable en cada rango correspondiente.


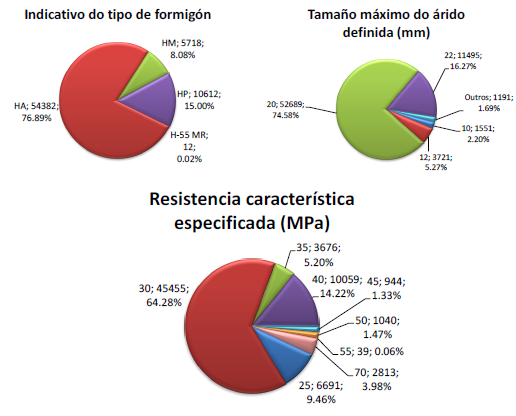 |
| Figura 1. Cantidad de probetas por tipo de hormigón |




...
 |
| Figura 2. Cantidad de cemento empleado |
 |
| Figura 3. Distribución por consistencias |
 |
| Figura 4. Relación a/c definida |
 |
| Figura 5. Resistencia alcanzada por cada probeta |
4.2 VARIABLES QUE AFECTAN A PROPIEDADES DEL HORMIGÓN
Continúa en: http://carreteras-laser-escaner.blogspot.com/2014/12/2-development-and-improvement-of.html
No hay comentarios:
Publicar un comentario