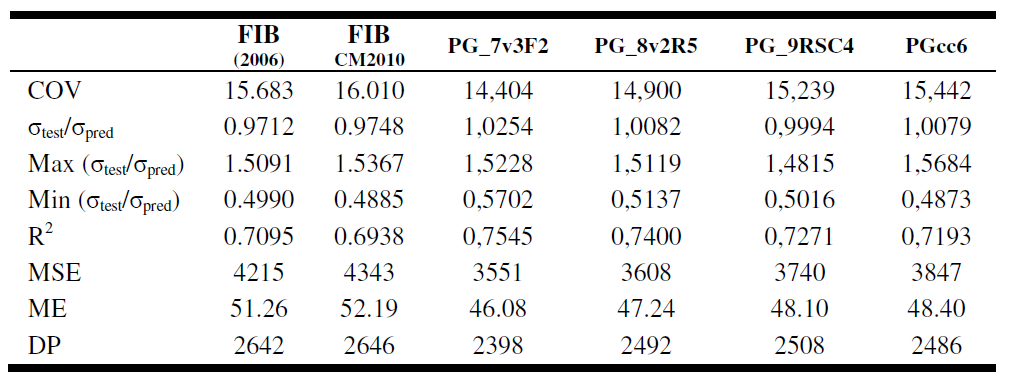
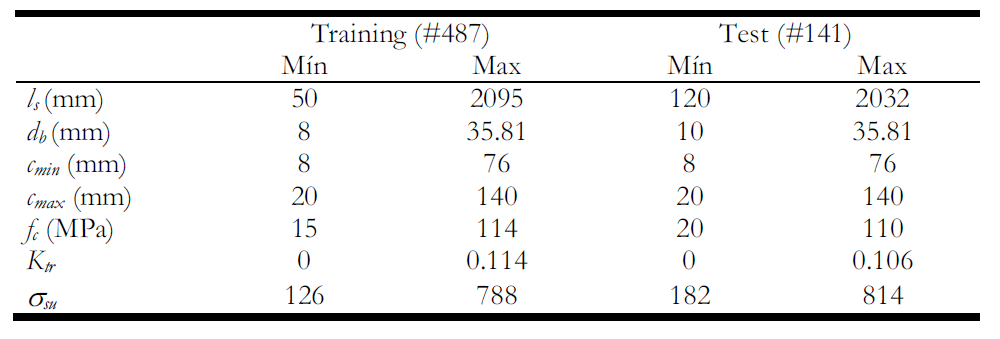
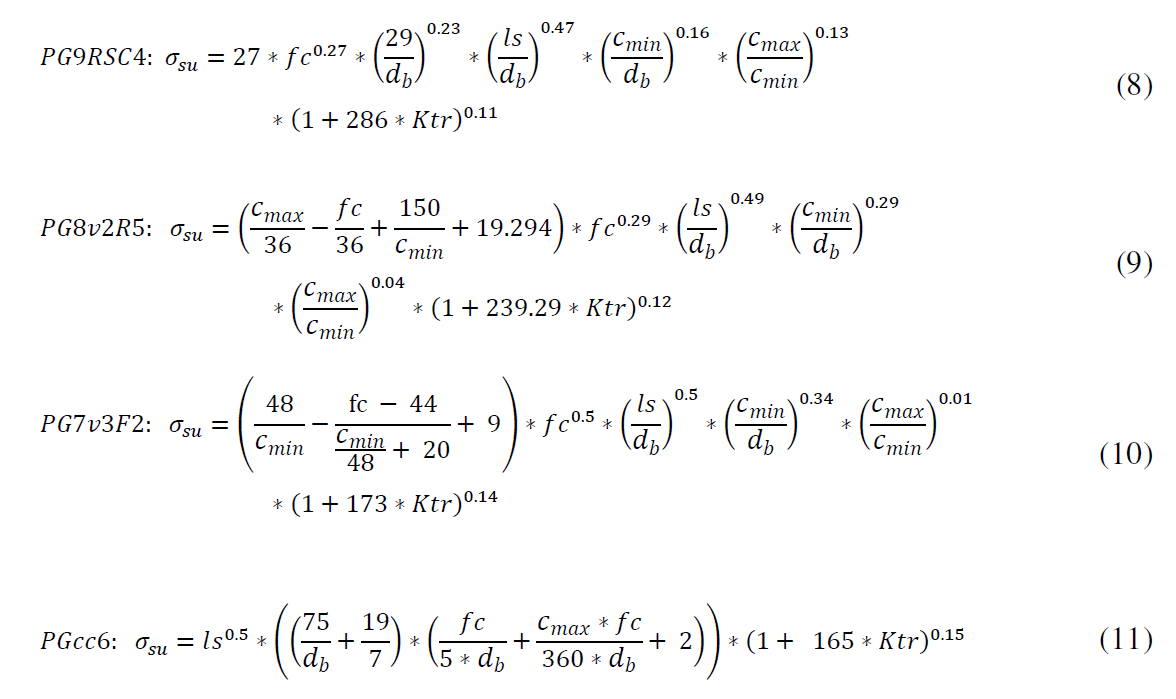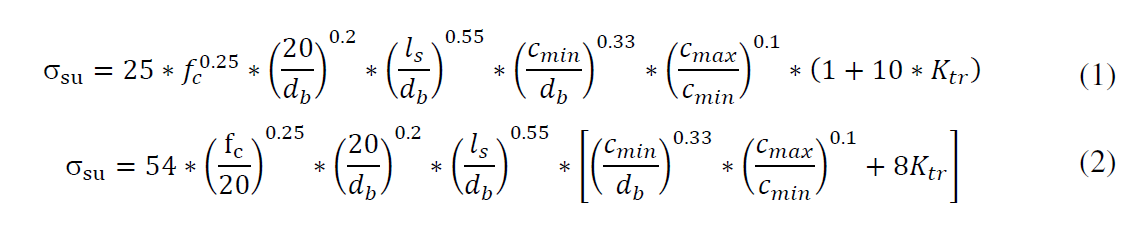Sea f, el valor que satisfaga /
Let f, the value that satisfies: af + bf = cf.
La direfencia con Fermat es que no obligaremos a que f sea un número natural. En su lugar buscaremos números f reales.
The difference with Fermat is that we will not force "f" was a natural number. Instead look real numbers for "f".
Conjuntos de tres / Sets of three elements
Lo primero es buscar el orden en las ternas {a, b, c}. La forma más fácil ser buscar los conjuntos que cumplan que la suma de sus elementos sean un número determinado y que c>a || b>a.
The first is to find order in the triples {a, b, c}. The easiest way to find the sets be satisfying than the sum of its elements are a certain number and c> a || b> a.
C(3) = {Ø}, 0 elementos.
C(4) = {( 1 1 2)} 1 elementos.
C(5) = {( 1 1 3), ( 1 2 2)} 2 elementos.
C(6) = {( 1 1 4), ( 1 2 3), ( 2 2 2)} 3 elementos.
C(7) = {( 1 1 5), ( 1 2 4), ( 1 3 3), ( 2 2 3)}
C(8) = {( 1 1 6), ( 1 2 5), ( 1 3 4), ( 2 2 4), ( 2 3 3)}
...
C(20) = {( 1 1 18), ( 1 2 17), ( 1 3 16), ( 1 4 15), ( 1 5 14), ( 1 6 13), ( 1 7 12), ( 1 8 11), ( 1 9 10), ( 2 2 16), ( 2 3 15), ( 2 4 14), ( 2 5 13), ( 2 6 12), ( 2 7 11), ( 2 8 10), ( 2 9 9), ( 3 3 14), ( 3 4 13), ( 3 5 12), ( 3 6 11), ( 3 7 10), ( 3 8 9), ( 4 4 12), ( 4 5 11), ( 4 6 10), ( 4 7 9), ( 4 8 8), ( 5 5 10), ( 5 6 9), ( 5 7 8), ( 6 6 8), ( 6 7 7)} 33 elementos.
Por si alguno tiene curiosidad el número de elementos de cada conjunto es:
In case anyone was curious, the number of elements in each set is:
( 2 0), ( 3 0), ( 4 1), ( 5 1), ( 6 2), ( 7 3), ( 8 4), ( 9 5), ( 10 7), ( 11 8), ( 12 10), ( 13 12), ( 14 14), ( 15 16), ( 16 19), ( 17 21), ( 18 24), ( 19 27), ( 20 30), ( 21 33), ( 22 37), ( 23 40), ( 24 44), ( 25 48), ( 26 52), ( 27 56), ( 28 61), ( 29 65), ( 30 70), ( 31 75), ( 32 80), ( 33 85), ( 34 91), ( 35 96), ( 36 102), ( 37 108), ( 38 114), ( 39 120), ( 40 127), ( 41 133), ( 42 140), ( 43 147), ( 44 154), ( 45 161), ( 46 169), ( 47 176), ( 48 184), ( 49 192), ( 50 200), ( 51 208), ( 52 217), ( 53 225), ( 54 234), ( 55 243), ( 56 252), ( 57 261), ( 58 271), ( 59 280), ( 60 290), ( 61 300), ( 62 310), ( 63 320), ( 64 331), ( 65 341), ( 66 352), ( 67 363), ( 68 374), ( 69 385), ( 70 397), ( 71 408), ( 72 420), ( 73 432), ( 74 444), ( 75 456), ( 76 469), ( 77 481), ( 78 494), ( 79 507), ( 80 520), ( 81 533), ( 82 547), ( 83 560), ( 84 574), ( 85 588), ( 86 602), ( 87 616), ( 88 631), ( 89 645), ( 90 660), ( 91 675), ( 92 690), ( 93 705), ( 94 721), ( 95 736), ( 96 752), ( 97 768), ( 98 784), ( 99 800), ( 100 817), ( 101 833),

Satisface la ecuación: y = 0,0833x2 - 0,1663x - 0,0207
Pero esto nos despista de nuestro objetivo
La idea / The idea
Una vez ordenados los conjuntos C(n) buscar los f de cada elemento del conjunto y ver que pinta tienen.Para cumplir este objetivo lo primero que hay que hacer es programar una función para calcular f conociendo a, b y c.
Once ordered sets C (n), we have to find the f of each element of the set and see how they are. To meet this objective the first thing to do is to make an function to calculate b and c knowing f.
Function CalculaFa(ByVal a As Integer,
ByVal b As Integer,
ByVal c As Integer) As Double
g = 0:p = 0.1:i1 = Sgn(a ^ g + b ^ g - c ^ g)
100:
Do
i0 = i1: g = g + p
h1 = a ^ g + b ^ g - c ^ g
i1 = Sgn(h1)
Loop Until i0 <> i1
p = -p / 10
If Abs(p) > 0.0000001 Then GoTo 100
CalculaFa = g
End Function
Resultado numérico: / Numerical results:
C(5):
(1 1 3)→0,630930
(1 2 2)→Inf.
C(6):
(1 1 4)→0,500000
(1 2 3)→1,000000
(2 2 2)→Inf.
C(7):
(1 1 5)→0,430677
(1 2 4)→0,694242
(1 3 3)→Inf.
(2 2 3)→1,709511
C(8):
(1 1 6)→0,386853
(1 2 5)→0,563896
(1 3 4)→1,000000
(2 2 4)→1,000000
(2 3 3)→Inf.
C(9):
(1 1 7)→0,356207
(1 2 6)→0,489536
(1 3 5)→0,727160
(1 4 4)→Inf.
(2 2 5)→0,756471
(2 3 4)→1,507127
(3 3 3)→Inf.
C(10):
(1 1 8)→0,333333
(1 2 7)→0,440660
(1 3 6)→0,600967
(1 4 5)→1,000000
(2 2 6)→0,630930
(2 3 5)→1,000000
(2 4 4)→Inf.
(3 3 4)→2,409421
C(11):
(1 1 9)→0,315465
(1 2 8)→0,405685
(1 3 7)→0,525764
(1 4 6)→0,748222
(1 5 5)→Inf.
(2 2 7)→0,553295
(2 3 6)→0,787885
(2 4 5)→1,421586
(3 3 5)→1,356916
(3 4 4)→Inf.
| C(12):
(1 1 10)→0,301030
(1 2 9)→0,379195
(1 3 8)→0,474995
(1 4 7)→0,626250
(1 5 6)→1,000000
(2 2 8)→0,500000
(2 3 7)→0,668850
(2 4 6)→1,000000
(2 5 5)→Inf.
(3 3 6)→1,000000
(3 4 5)→2,000000
(4 4 4)→Inf.
C(13):
(1 1 11)→0,289065
(1 2 10)→0,358299
(1 3 9)→0,438018
(1 4 8)→0,551463
(1 5 7)→0,763203
(1 6 6)→Inf.
(2 2 9)→0,460846
(2 3 8)→0,591710
(2 4 7)→0,807572
(2 5 6)→1,372508
(3 3 7)→0,818068
(3 4 6)→1,293174
(3 5 5)→Inf.
(4 4 5)→3,106284
C(14):
(1 1 12)→0,278943
(1 2 11)→0,341305
(1 3 10)→0,409664
(1 4 9)→0,500000
(1 5 8)→0,645009
(1 6 7)→1,000000
(2 2 10)→0,430677
(2 3 9)→0,537187
(2 4 8)→0,694242
(2 5 7)→1,000000
(2 6 6)→Inf.
(3 3 8)→0,706695
(3 4 7)→1,000000
(3 5 6)→1,822550
(4 4 6)→1,709511
(4 5 5)→Inf.
| C(15):
(1 1 13)→0,270238
(1 2 12)→0,327153
(1 3 11)→0,387098
(1 4 10)→0,462006
(1 5 9)→0,571072
(1 6 8)→0,774576
(1 7 7)→Inf.
(2 2 11)→0,406598
(2 3 10)→0,496338
(2 4 9)→0,618529
(2 5 8)→0,821352
(2 6 7)→1,339977
(3 3 9)→0,630930
(3 4 8)→0,836778
(3 5 7)→1,256656
(3 6 6)→Inf.
(4 4 7)→1,238613
(4 5 6)→2,487939
(5 5 5)→Inf.
C(16):
(1 1 14)→0,262650
(1 2 13)→0,315140
(1 3 12)→0,368624
(1 4 11)→0,432581
(1 5 10)→0,519463
(1 6 9)→0,659684
(1 7 8)→1,000000
(2 2 12)→0,386853
(2 3 11)→0,464425
(2 4 10)→0,563896
(2 5 9)→0,712809
(2 6 8)→1,000000
(2 7 7)→Inf.
(3 3 10)→0,575717
(3 4 9)→0,731774
(3 5 8)→1,000000
(3 6 7)→1,719845
(4 4 8)→1,000000
(4 5 7)→1,581624
(4 6 6)→Inf.
(5 5 6)→3,801784
| C(17):
(1 1 15)→0,255958
(1 2 14)→0,304786
(1 3 13)→0,353161
(1 4 12)→0,408985
(1 5 11)→0,480955
(1 6 10)→0,586741
(1 7 9)→0,783603
(1 8 8)→Inf.
(2 2 13)→0,370310
(2 3 12)→0,438694
(2 4 11)→0,522352
(2 5 10)→0,638731
(2 6 9)→0,831677
(2 7 8)→1,316498
(3 3 11)→0,533484
(3 4 10)→0,658051
(3 5 9)→0,849761
(3 6 8)→1,232521
(3 7 7)→Inf.
(4 4 9)→0,854756
(4 5 8)→1,207399
(4 6 7)→2,215951
(5 5 7)→2,060043
(5 6 6)→Inf.
C(18):
(1 1 16)→0,250000
(1 2 15)→0,295743
(1 3 14)→0,339986
(1 4 13)→0,389554
(1 5 12)→0,450889
(1 6 11)→0,535259
(1 7 10)→0,671597
(1 8 9)→1,000000
(2 2 14)→0,356207
(2 3 13)→0,417433
(2 4 12)→0,489536
(2 5 11)→0,584449
(2 6 10)→0,727160
(2 7 9)→1,000000
(2 8 8)→Inf.
(3 3 12)→0,500000
(3 4 11)→0,603151
(3 5 10)→0,749960
(3 6 9)→1,000000
(3 7 8)→1,651588
(4 4 10)→0,756471
(4 5 9)→1,000000
(4 6 8)→1,507127
(4 7 7)→Inf.
(5 5 8)→1,474770
(5 6 7)→2,973549
(6 6 6)→Inf.
| C(19)
(1 1 17)→0,244651
(1 2 16)→0,287761
(1 3 15)→0,328594
(1 4 14)→0,373214
(1 5 13)→0,426624
(1 6 12)→0,496517
(1 7 11)→0,599669
(1 8 10)→0,791002
(1 9 9)→Inf.
(2 2 15)→0,344010
(2 3 14)→0,399514
(2 4 13)→0,462854
(2 5 12)→0,542693
(2 6 11)→0,654699
(2 7 10)→0,839780
(2 8 9)→1,298569
(3 3 13)→0,472707
(3 4 12)→0,560499
(3 5 11)→0,678323
(3 6 10)→0,859418
(3 7 9)→1,215158
(3 8 8)→Inf.
(4 4 11)→0,685198
(4 5 10)→0,867160
(4 6 9)→1,186814
(4 7 8)→2,057504
(5 5 9)→1,179250
(5 6 8)→1,867720
(5 7 7)→Inf.
(6 6 7)→4,496556
| C(20):
(1 1 18)→0,239813
(1 2 17)→0,280648
(1 3 16)→0,318622
(1 4 15)→0,359240
(1 5 14)→0,406541
(1 6 13)→0,466065
(1 7 12)→0,548456
(1 8 11)→0,681533
(1 9 10)→1,000000
(2 2 16)→0,333333
(2 3 15)→0,384168
(2 4 14)→0,440660
(2 5 13)→0,509415
(2 6 12)→0,600967
(2 7 11)→0,738690
(2 8 10)→1,000000
(2 9 9)→Inf.
(3 3 14)→0,449966
(3 4 13)→0,526285
(3 5 12)→0,624114
(3 6 11)→0,763919
(3 7 10)→1,000000
(3 8 9)→1,602326
(4 4 12)→0,630930
(4 5 11)→0,774279
(4 6 10)→1,000000
(4 7 9)→1,457470
(4 8 8)→Inf.
(5 5 10)→1,000000
(5 6 9)→1,412357
(5 7 8)→2,605651
(6 6 8)→2,409421
(6 7 7)→Inf.
... | C(25):
(1 1 23)→0,221065
(1 2 22)→0,253971
(1 3 21)→0,282600
(1 4 20)→0,311047
(1 5 19)→0,341358
(1 6 18)→0,375361
(1 7 17)→0,415359
(1 8 16)→0,464959
(1 9 15)→0,530840
(1 10 14)→0,628226
(1 11 13)→0,807162
(1 12 12)→Inf.
(2 2 21)→0,294784
(2 3 20)→0,331166
(2 4 19)→0,368173
(2 5 18)→0,408588
(2 6 17)→0,455182
(2 7 16)→0,511801
(2 8 15)→0,584974
(2 9 14)→0,688046
(2 10 13)→0,856493
(2 11 12)→1,262874
(3 3 19)→0,375521
(3 4 18)→0,421736
(3 5 17)→0,473532
(3 6 16)→0,535062
(3 7 15)→0,612636
(3 8 14)→0,717976
(3 9 13)→0,878073
(3 10 12)→1,182930
(3 11 11)→Inf.
(4 4 17)→0,479051
(4 5 16)→0,545214
(4 6 15)→0,626613
(4 7 14)→0,733936
(4 8 13)→0,889217
(4 9 12)→1,151962
(4 10 11)→1,817457
(5 5 15)→0,630930
(5 6 14)→0,741031
(5 7 13)→0,894776
(5 8 12)→1,137374
(5 9 11)→1,623440
(5 10 10)→Inf.
(6 6 13)→0,896477
(6 7 12)→1,131270
(6 8 11)→1,552882
(6 9 10)→2,720194
(7 7 11)→1,533562
(7 8 10)→2,436346
(7 9 9)→Inf.
(8 8 9)→5,884949
|
Resultado gráfico: / Graphic results:
Cada banda vertical es un número f, azul para C(1) y rojo para C(255) según arco iris
Each vertical strip is a number f, blue for C (1) and red for C (255) according rainbow scale.
Ídem, pero en lugar de formar una banda vertical, forma un punto y en ordenadas el valor de x de C(x).
Idem, but instead of forming a vertical band, it forms a neat point and the value of x in C (x).
Salvo ante valores de 0, 1 y 2 parece que los némeros "f" rehuyeran los demás números enteros, y quebrados y similares. Se puede concluir que: "x Î R, $ fÎ[x-e,x+e]Î R & a,b,c Î N | af+bf=cf .
Es decir, dado un número real, x, siempre existe un número real en el intervalo
[x-e,x+e] que satisface la ecuación af+bf=cf
con valores enteros de a,b y c.
Pongamos un ejemplo. Sea x=3, vamos a ver cómo podemos aproximarnos:
C(10); (3 3 4); f = 2,409421; e = 0,590579
C(13); (4 4 5); f = 3,106284; e = 0,106283
C(18); (5 6 7); f = 2,973549; e = 2,645111·10-02
C(23); (6 8 9); f = 2,993245; e = 6,755113·10-03
C(31); (9 10 12); f = 3,002552; e = 2,552032·10-03
C(82); (15 33 34); f = 3,002088; e = 2,088069·10-03
C(98); (17 40 41); f = 2,998646; e = 1,353979·10-03
C(113); (23 44 46); f = 3,001228; e = 1,228094·10-03
C(119); (36 37 46); f = 2,998798; e = 1,202106·10-03
C(120); (24 47 49); f = 2,999859; e = 1,409053·10-04
C(166); (43 58 65); f = 2,999891; e = 1,089572·10-04
C(216); (41 86 89); f = 3,000106; e = 1,060962·10-04
C(261); (64 94 103); f = 3,000005; e = 5,006790·10-06
C(353); (71 138 144); f = 2,999997; e = 3,099441·10-06
C(445); (135 138 172); f = 2,999999; e = 9,536743·10-06
La sucesión 10, 23, 28, 23, 31, 82, 98, 113, 119, 120, 166
, 216, 261, 353, 445,... ¿Tiene algún término general?
Para x=4
C(13); (4 4 5); f = 3,106284; e = 0,8937160
C(16); (5 5 6); f = 3,801784; e = 0,1982159
C(24); (7 8 9); f = 3,941391; e = 5,860900·10-02
C(37); (10 13 14); f = 4,026536; e = 2,653598·10-02
C(59); (18 19 22); f = 4,025973; e = 2,597284·10-02
C(67); (16 25 26); f = 3,982761; e = 1,723909·10-02
C(72); (17 27 28); f = 4,005021; e = 5,021095·10-03
C(94); (21 36 37); f = 3,999590; e = 4,100799·10-04
C(118); (37 37 44); f = 4,000348; e = 3,480911·10-04
C(184); (53 62 69); f = 3,999917; e = 8,296966·10-05
C(320); (64 127 129); f = 3,999935; e = 6,508827·10-05

Con e = 0,01 resulta:
C(23); (6 8 9); f = 2,993245
C(31); (9 10 12); f = 3,002552
C(46); (12 16 18); f = 2,993245
C(62); (18 20 24); f = 3,002552
C(69); (18 24 27); f = 2,993245
C(74); (19 26 29); f = 3,009558
C(75); (23 23 29); f = 2,990260
C(80); (23 26 31); f = 2,992867
C(82); (15 33 34); f = 3,002088
C(88); (27 27 34); f = 3,006838
C(91); (22 33 36); f = 2,991530
C(92); (24 32 36); f = 2,993245
[...]
C(171); (44 60 67); f = 3,007065
C(173); (50 56 67); f = 2,997841
[...]
Con e = 0,001 resulta:
C(120); (24 47 49); f = 2,999859
C(146); (31 56 59); f = 3,000988
C(163); (50 50 63); f = 2,999187
C(166); (43 58 65); f = 2,999891
C(179); (26 76 77); f = 3,000766
C(186); (40 71 75); f = 3,000602
[...]
C(319); (88 107 124); f = 2,999737
[...]
Con e = 0,0001 resulta:
C(261); (64 94 103); f = 3,000005
C(318); (94 101 123); f = 3,000042
C(328); (95 106 127); f = 3,000017
C(349);(103 111 135); f = 2,999970
C(353); (71 138 144); f = 2,999997
C(367); (73 144 150); f = 3,000003
C(374); (83 141 150); f = 3,000016
C(378); (54 161 163); f = 2,999991
C(380);(112 121 147); f = 2,999953
C(381); (44 168 169); f = 3,000049
C(400);(107 137 156); f = 2,999975
C(409);(102 146 161); f = 3,000080
C(411);(121 131 159); f = 2,999971
C(429); (59 184 186); f = 3,000089
C(432);(130 135 167); f = 2,999918
C(442);(130 141 171); f = 3,000009
C(445);(135 138 172); f = 2,999999
C(451);(120 155 176); f = 3,000087
[...]
De todo esto se puede deducir que si bien el teorema de Fermat se cumple para un matemático, sin embargo, se incumple para un ingeniero (si se admite un pequeño error). :-)
From all this, it can be deduced that although Fermat's theorem is true for a mathematician, however, fails to engineer (if a little error is supported). :-)
Queda ver que pasa cuando f forme parte de los números complejos.
It remains to see what happens when f was part of the complex numbers.